
生命编码背后的故事(卌三)
基因测序

在基因泰克公司成功上市的1980年10月初,斯坦福大学的伯格接到来自斯德哥尔摩的电话。他因为“针对核酸生物化学的基础性研究,尤其是DNA重组”贡献赢得那年的诺贝尔化学奖。
不到两个月后,伯耶和科恩为基因重组技术申请的专利历经六年法律纠纷后终于开始获得批准,1开创分子生物学技术专利化的先河。然而似乎有得必有失,同为基因重组先驱的伯耶和科恩没能与伯格分享表彰这项重大突破的诺贝尔奖。
伯格倒也不是那年诺贝尔化学奖的唯一得主。那年的奖金被一分为二,其中一半归伯格所得。另一半由另外两位生物化学家分享。他们的获奖缘由——成功地为DNA分子测序——与伯格的DNA重组没有直接关联。两人之一正是22年前已经因为蛋白质分子测序而得过诺贝尔奖的桑格。
构成生命主体的蛋白质、核糖核酸和脱氧核糖核酸都属于结构上相对简单的长链型有机大分子。蛋白质由20种氨基酸相接而成,其中不同的氨基酸组合和顺序决定着蛋白质分子折叠出的外在形状及其物理、化学性质。自桑格早年成功测序后,生物化学家对蛋白质分子的认识已经相当深入。
RNA和DNA长链中的主体则是碱基或由碱基通过互补的氢键组成的碱基对。它们的序列正是组装蛋白质的蓝图,也就是生命的编码。
从孟德尔由观察到的豌豆遗传规律猜测生物体中存在有某种遗传因子,到摩尔根沿着染色体标志他们辨识出的果蝇基因位置,到德尔布吕克和薛定谔猜测基因可能是染色体中储存于非周期性晶体分子中的编码,人类经过100多年的摸索终于在20世纪中期认识DNA的双螺旋结构和其中编码的运作方式:每三个碱基组成一个密码子,对应于一种氨基酸。这些编码信息由DNA分子“转录”给作为信使的mRNA分子,然后在细胞工厂中组装成蛋白质。是为分子生物学之中心法则。
生命的蓝图至此已然触手可及。那是在DNA和RNA分子中以碱基写就的蛋白质设计规划。每个碱基——腺嘌呤(A)、鸟嘌呤(G)、胞嘧啶(C)、胸腺嘧啶(T)或尿嘧啶(U)——都是其中的一个“字”。单个的字本身没有含义,但三个字一组的密码子构成有意义的“词”,代表着氨基酸。基因则是由这些词写就的句子,表达的就是蛋白质中的氨基酸长链顺序。
当全部的密码子在1960年代被尼伦伯格等人逐一破解后,人类已经掌握核酸编码这本天书中的全部词汇。当然只有词典还不够,还需要像桑格解析胰岛素中氨基酸序列一样为DNA、RNA分子中的碱基测序,才能够由字、词到句子般读懂生命的奥秘。
发明蛋白质测序方法之后,桑格没有立即转向核酸分子的测序。那时候,这个似乎是自然而然的下一个目标在他看来尚且遥不可及。
在为胰岛素等蛋白质测序时,桑格选用合适的酶将它们的长链切成只含非常少量氨基酸分子的碎片,然后通过辨认碎片末端的氨基酸和碎片之间的重叠逐步理清整条长链的序列。那时,能够同样地切割核酸长链的酶尚未被分离。桑格因而无法将同样的方法直接应用于核酸测序。胰岛素分子中只有51个氨基酸分子,而氨基酸也有着多达20的种类。为胰岛素测序时,它们的碎片不太多,不同氨基酸分子形成的多种排列组合也使得辨认不同碎片间的重叠较为容易。核酸的情形却正好相反。即使最简单细菌的DNA就有着5000来个碱基对。碱基又只有四种,过于单调。即使将核酸长链切碎,大量的不同碎片末端也会有高度的重复率,难以确定碎片之间的衔接关系。再则,桑格也找不到足够纯度的核酸样品。如此困难重重,虽然他所在的剑桥分子生物学实验室里有克里克等偏爱核酸的专家在持续地激励、督促,桑格只是按兵不动。
十多年后,高纯度的RNA样品和切割其长链的酶陆续出现。康奈尔大学的霍利(Robert Holley)在1964年先发制人,率先实现针对RNA的测序。他选择的是RNA中最小、最简单的tRNA,即克里克最早想象出的适配器分子。专门组装丙氨酸的tRNA分子中只有77个碱基,与胰岛素中的氨基酸数目相差无几。霍利因而行之有效地应用桑格的蛋白质测序步骤获得成功。因为这一成就,霍利在1968年赢得诺贝尔生理学或医学奖,与最早破解DNA密码子的尼伦伯格和另一位生物化学家共享殊荣。
桑格随后也用另一种方式成功测定tRNA的碱基序列。但无论是霍利还是他自己的方法都无法推广到碱基数目多得太多的DNA。那显然还需要另辟蹊径。
也是在康奈尔的分子生物学家吴瑞(Ray Wu)随即提出一个出奇制胜的方式。吴瑞的父亲是当年在北平协和医学院最早提出蛋白质在遇热或外力打击时失去原有状态的“变性”是因为分子折叠形状发生变化的吴宪。他们一家在1949年离开中国时吴瑞刚过20岁,在美国接受大学、研究生教育后成为康奈尔大学的教授。2在1960年代末,吴瑞突发奇想,认为DNA测序时没有必要像对付蛋白质那样将分子长链切碎、拼接。无论是在生物体内,还是在“体外”的试管环境中,DNA都会不断地自我复制。每次复制时,它们原来的双螺旋被打开。两条长链各自在特定的酶帮助下按顺序一个接一个地与互补的碱基分子结合形成新的长链。如果能在这个过程中设法“偷窥”、记录那些正在被结合的碱基分子,便可以获取完整的DNA碱基序列。运用这一技巧,吴瑞成功地测定一个只有12个碱基DNA小片段中的序列。
然而,DNA复制时的组装速度相当之快,很难及时偷窥那一个又一个的碱基分子运作。但在吴瑞实验的启发下,桑格终于找到一个迫使DNA复制停滞的方法,得以足够的时间细致观察其组装过程。
DNA的长链中除了碱基之外还有脱氧核糖和磷酸。这三种分子结合组成核苷酸分子。复制时,所需的碱基分子也是先与脱氧核糖和磷酸组装成核苷酸,然后将再以氢键与已经打开的长链结合。这其中的脱氧核糖是缺失一颗氧原子的核糖分子,其中的一个羟基变成孤零零的氢原子(见《十四:脱氧核糖》中的核糖分子结构图)。
脱氧核糖分子中还有另外的由氢原子和氧原子组成的羟基,因而也还可以继续“脱氧”。同时缺失两颗氧原子的核糖分子便是“双脱氧”(dideoxy)核糖。因为化学性质与更常见的脱氧核糖大同小异,双脱氧核糖分子也能混迹在脱氧核糖中,同样地与碱基和磷酸分子构成“双脱氧核苷酸”(dideoxynucleotide),被毫无防范之心的酶用来组装新的DNA双螺旋长链。
不过双脱氧核苷酸固然能在DNA组装过程中蒙混过关,它们的行踪还是会即刻暴露无疑。一旦双脱氧核苷酸出现在DNA长链上,其与脱氧核苷酸“小异”的化学性质会造成正在复制中的长链无法再接纳下一个脱氧核苷酸。于是,长链的的复制戛然而止,不再能继续。
桑格在试管中有意掺入带有某个碱基分子的双脱氧核苷酸分子,让DNA在这样的“体外”环境中复制。因为复制中的DNA分子会在不同的时机遭遇双脱氧核苷酸,试管中于是留下大量半途而废的DNA片段。这些“废料”中已经完成复制的部分长短不一,终止的位置各为相异。但每个终止点都是那个碱基在该DNA长链中的位置。利用化学家早已熟悉的“电泳”(electrophoresis)、“放射自显影(autoradiograph)等物理手段,桑格可以分离出这些前功尽弃的DNA碎片,分别测量它们的长度。只要由足够的废料,他这样能探测出那个碱基分子在DNA长链中可能出现的全部位置。
如果分别使用带有四种不同碱基分子的双脱氧核苷酸进行同样的实验,将所有的碎片按长度排列,它们终止点的双脱氧核苷酸中所含的碱基分子便还原出DNA中的全部碱基序列。或更准确而言,还原出的是与原来碱基互补(A与T、C与G互换)的序列。
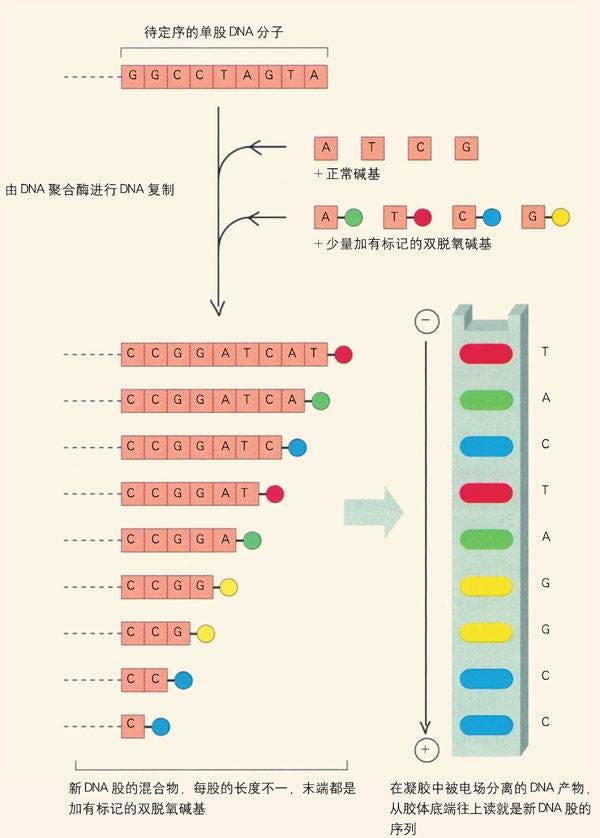
因为不需要人为地切断、复原DNA长链,这个方法可以有效地应用于碱基分子数量众多的DNA分子。然而,尽管原理直截了当,这也是一个极其繁杂且乏味的实验。那时现成的双脱氧核苷酸还只有一种,其中带有胸腺嘧啶。桑格不得不与助手们从头开始,人工合成带有另外三种碱基的双脱氧核苷酸分子。经过多年埋头苦干,他们终于在1977年成功地解析出一种噬菌体的DNA序列,其中含有5000多个碱基对。
桑格已经到了花甲之年。历经蛋白质、RNA和DNA测序的他终于心满意足的认可这个DNA测序方法是自己一辈子科研生涯中最漂亮的新思想,既是十分的原创又非常地成功。仅仅三年后,桑格再度荣获诺贝尔化学奖。不过这一次他没能独占花魁。哈佛大学的吉尔伯特也发现了一种不同的DNA测序法,同时得到诺贝尔奖的青睐。两人分享1980年诺贝尔化学奖中伯格之外的那一半。

直到今天,桑格还是唯一的两次诺贝尔化学奖获得者。在他之前,物理学家巴丁(John Bardeen)已经分别在1956和1972年两次赢得诺贝尔物理奖。居里夫人和鲍林也曾两获诺贝尔奖,但他们获得的是不同的奖项:居里夫人分别获得物理奖和化学奖,鲍林则是化学奖与和平奖。巴丁和桑格因而是绝无仅有的同一项诺贝尔科学奖两次获得者。
几乎与桑格和吉尔伯特各自为DNA测序的同时,美国分子生物学家罗伯茨(Richard Roberts)和夏普(Phillip Sharp)却赫然发现DNA中的碱基序列并不都是克里克所描述的生命编码。它们之中还藏有更多的惊奇。
克里克的中心法则清楚地描述生命编码的运作过程:DNA中的蛋白质编码——由A、C、G、T四个字(碱基)写成的长句子——首先“转录”给担任信使角色的mRNA分子,由后者传送到细胞核外在tRNA和酶的协助下再“翻译”、组装成蛋白质的氨基酸序列。这个过程中的第一步最为简单直接:DNA中的每个字都如实地被抄写给mRNA,只是其中的T(胸腺嘧啶)被改换为U(尿嘧啶)。mRNA中的编码因而是以A、C、G、U四个字写就,但无论是它们组成的词还是句子都与DNA中的原始编码毫无二致。
这正是克里克曾经强调过的“共线性”:核酸中的碱基序列与蛋白质中的氨基酸序列平行等同,由前者完全决定后者。组装蛋白质的转录、翻译过程必须按其顺序持续地阅读碱基序列中的每一个字和词,既不能重复也不能跳跃,否则可能造成移码突变。
然而,冷泉港实验室的罗伯茨和麻省理工学院的夏普却在1977年各自独立地发现只是细菌中的基因才是这样简洁明了的句子。比细菌复杂得多的动物DNA分子中以碱基序列写就的句子却更接近于杂乱无章,其中描述氨基酸的词之间混杂有大量多余的内容。那些夹在中间的碱基看起来似乎是基因的一部分,其实根本没有对应蛋白质中的任何氨基酸。这些鱼目混珠的“杂质”打破了克里克的“共线性”,将DNA中描述氨基酸序列的句子阻隔成无数断断续续的不连贯词组,压根无从阅读。
当然地球上的生命兴旺蓬勃,丝毫没有被蛋白质编码中的混乱所干扰。显然,生命在编码运作过程中也有着去粗取精去伪存真的步骤,可以游刃有余地对付DNA中的杂质。果然,罗伯茨和夏普发现编码从DNA到mRNA的转录不是克里克想象的一蹴而就,至少存在有两个分立的步骤。
首先,DNA中的碱基编码的确如克里克描述那样忠实地转录到mRNA分子中。如此生成的mRNA与DNA一样带着良莠混杂的编码,只是所谓的“前体mRNA”(precursor mRNA)。随后,这些前体mRNA会紧接着进行自我净化,在一些酶的帮助下将混在编码句子中冗余的碱基序列尽数剔除。如此后期加工留下的“成熟mRNA”(mature mRNA)才是真正的信使RNA。它们的碱基序列完整地保留着、也只保留着组装蛋白质所需的编码信息。罗伯茨和夏普将这个自我净化步骤称作“RNA剪接”(RNA splicing)。剪除多余的累赘再重新接好的碱基序列在成熟mRNA中才终于成为一个连续、紧凑的句子。
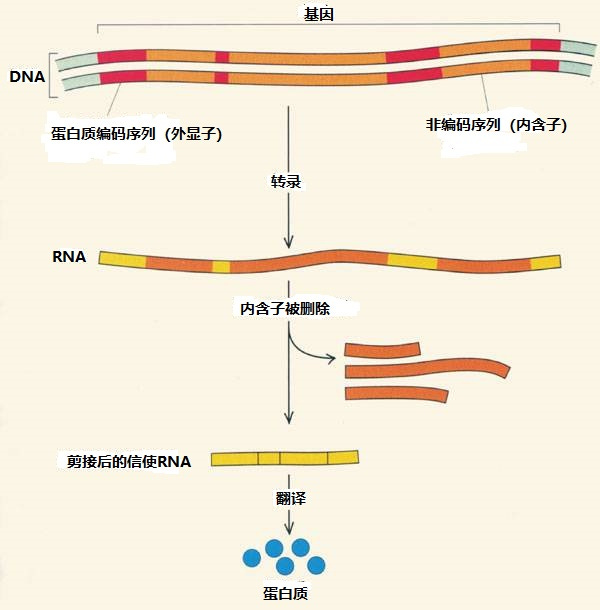
这个过程相当匪夷所思。尤其是那些无意义的碱基成分在DNA中远远多于有意义的成分,实在是喧宾夺主。但罗伯茨和夏普的发现很快在几乎同时出现的DNA测序中得到证实。吉尔伯特将那些在DNA分子中滥竽充数的碱基命名为“内含子”(intron)。这也是一个生造的名词,来自“基因内部区域”(intragenic region)的缩写。相应地,处于这些“内部区域”之外、真正为蛋白质编码的碱基则被称为“外显子”(exon)。DNA和前体mRNA的碱基长链都是内含子和外显子的混合。只有经历过RNA剪接的成熟mRNA中才是洁净的蛋白质编码,不再参杂无意义的内含子。
因为这一惊人发现,罗伯茨和夏普在十多年后赢得1993年诺贝尔生理学或医学奖。
罗伯茨和夏普做出他们出乎意料的发现时,克里克的中心法则正好问世整整20年。无数分子生物学实验已经证明克里克当年的远见。内含子的存在和RNA剪接固然令人惊讶莫名,对于中心法则来说也只是一个不那么重要的修正。
20多年前,克里克首先在RNA俱乐部内的非正式通信中提出他的想法,有点哗众取宠地采用英文“dogma”一词命名这个“法则”。他的原意是这些法则类似于科学理论中不证自明的“原理”,是分子生物学的基础。虽然是土生土长的英国人,克里克却没有意识到这个英文词的本意其实是宗教性质的“教条”。
在陆续求证中心法则的同时,分子生物学家也热衷于挑战这一“教条”。早在1970年,也是在麻省理工学院的巴尔的摩3也发现过一个似乎与中心法则截然相反的过程:有些病毒自身只有RNA,没有DNA。它们将RNA注入细菌细胞时能产生一种酶,将自己的RNA转变成DNA融入宿主。这个过程与以“DNA --> RNA --> 蛋白质”信息传递方向为标志的中心法则反其道而行,故被称为“逆向转录”(reverse transcription)。其中的酶也被命名为“逆转录酶”(reverse transcriptase)。巴尔的摩和另外同时做出这一发现的分子生物学家一起在1975年获得诺贝尔生理学或医学奖。那年年初,他也曾协助伯格组织阿西洛马会议。
“DNA --> RNA --> 蛋白质”的始作俑者沃森一直将巴尔的摩等人的发现界定为中心法则中少有的反例。克里克却不以为然,多次解释他的中心法则其实并未否定过遗传信息从RNA传递到DNA的可能性(见《卅六:中心法则》中克里克手绘中心法则示意图中的虚线)。但这个历史的误会持续至今。
这个逆向的“反例”倒是帮了吉尔伯特的忙。
吉尔伯特比沃森年轻四岁。他从小喜爱物理学,17岁时曾赢得久负盛名的“西屋科学天才奖”4。沃森在1956年到哈佛任教时,吉尔伯特刚刚在剑桥获得物理博士学位,导师是著名的理论物理学家萨拉姆(Abdus Salam)。在剑桥求学期间,吉尔伯特正赶上沃森和克里克的轰动性发现。虽然与他钻研的量子场论(quantum field theory)毫不相干,吉尔伯特也经常关顾卡文迪许实验室,一边仰慕那个双螺旋模型一边与沃森相谈甚欢。
获得博士学位后,吉尔伯特回到母校哈佛,踌躇满志地开启自己的物理学生涯。但他还是对DNA的双螺旋以及其中蕴藏着的生命奥秘难以忘怀。与早先在加州理工学院的前辈费曼一样,吉尔伯特也频繁走访沃森的实验室。但他并非浅尝辄止,反而深陷其中不可自拔,以至于逐渐放弃理论物理,一头扎进分子生物学实验。虽然大跨界改行,吉尔伯特不久便有了重大收获,与沃森一起分离出mRNA分子,为克里克的中心法则提供举足轻重的证明。1970年时,他又分离出能够抑制基因转录的蛋白质分子,证实雅各布和莫诺的基因调控猜想。
在那短短十来年里,吉尔伯特在哈佛的头衔也在不断演变,历经物理博士后、物理助理教授、生物物理副教授,最终成为生物化学教授。他的学术事业在1977年登峰造极,与桑格几乎同时成功地为DNA测序并共享1980年的诺贝尔化学奖5。
那个辉煌时刻到来时,吉尔伯特已经离开了哈佛大学。伯耶和斯旺森联手创办基因泰克公司的壮举在生物科学界和风险投资业都引起相当大的反响。在几位资深投资家的鼓励和资助下,吉尔伯特在1978年也毅然“下海”,与夏普等几位分子生物学教授一起创办“渤健”(Biogen)公司。那是继基因泰克之后出现的第二家生物工程公司。吉尔伯特没有像其他学者那样脚踏两条船,同时兼顾大学的教学和公司的创业。他辞去哈佛的教授职务,亲自担任渤健公司的总经理。虽然比基因泰克已经晚了两年,吉尔伯特看准的也是人工生产胰岛素这个诱人的商机。
他们的思路是直接从人体细胞中分离生产胰岛素的基因,将这个DNA片段植入大肠杆菌的细胞中令其生产人类急需的胰岛素。但吉尔伯特很快陷入困境。人体基因的DNA中有着大量的内含子,是大肠杆菌没见过的怪物。与动物、植物等“真核生物”(eukaryote)不同,大肠杆菌属于“原核生物”(prokaryote)。它们小巧简单,没有明确分离的细胞核。它们的DNA也更“纯洁”,其中没有真假难辨的内含子。因此,大肠杆菌的细胞中也没有专门进行RNA剪接的酶。面对人体基因中众多不伦不类的内含子,细菌的细胞工厂束手无策,无力制造胰岛素。
吉尔伯特于是“逆向”思维,借用巴尔的摩等人的发现利用病毒的逆转录酶将来自人体的成熟mRNA逆转成不再带有内含子的DNA,然后再植入细菌的细胞开启生产。但在解决这个技术难题后,吉尔伯特却遇到更大的麻烦。因为直接应用人体的DNA和RNA,他们的实验过程正属于阿西洛马会议所设定的四级风险,只能在最严格、最安全的实验室内进行。在那个年代,能满足这个“P4”要求的实验室凤毛麟角。吉尔伯特不得不求助于美国在欧洲的军事基地勉为其难。
经历这一系列困难和挫折,渤健公司最终在与基因泰克的激烈竞争中败下阵来。伯耶没有从人体中提取基因,而是根据胰岛素的氨基酸系列人工合成相应的DNA。他这样既避免了内含子的麻烦,也绕开了阿西洛马会议所定义的风险。阴错阳差地,那个他极为反感的阿西洛马决议却在关键时刻为他的商业成功提供及时的关键性援助。
尽管在胰岛素上失去先机,渤健还是在1984年伴随生物工程的大潮成功上市。但仅一年后,公司濒临破产。吉尔伯特被迫辞去总经理职务,回到哈佛重操旧业。那时,他也已经锁定一个新的挑战:为人类的全部基因测序,完整地揭示生命的蓝图。
(待续)
他们原先的专利申请被拆成三个分立的专利。1980年12月2日批准的是第一个。另两个还要分别等到1984和1988年才得到批准。
吴瑞(Ray Wu)后来在中国改革开放初期的1980年代创办“中美生物化学联合招生项目”(CUSBEA),协助中国学生赴美留学。
夏普和巴尔的摩都是已经在麻省理工学院担任系主任的卢里亚特意招揽的人才。卢里亚慧眼识才,至少发现四名未来的诺贝尔奖获得者。
Westinghouse Science Talent Search
吉尔伯特的导师萨拉姆在那一年前赢得1979年诺贝尔物理奖。